


word 文档中的批注通常用于协作审阅和反馈。这些批注可能包含文本和图片,它们为文档改进提供了重要的参考信息。提取批注中的文本和图片可以帮助你分析和评估审阅者的反馈,从而全面了解文档的优点、缺点以及改进建议。本文将演示如何使用 spire.doc for java 在 java 中提取 word 文档中的批注文本和图片。
安装 spire.doc for java
首先,您需要在 java 程序中添加 spire.doc.jar 文件作为依赖项。jar 文件可以从此链接下载。 如果您使用 maven,则可以将以下代码添加到项目的 pom.xml 文件中,从而轻松地在应用程序中导入 jar 文件。
com.e-iceblue
e-iceblue
https://repo.e-iceblue.cn/repository/maven-public/
e-iceblue
spire.doc
13.3.0
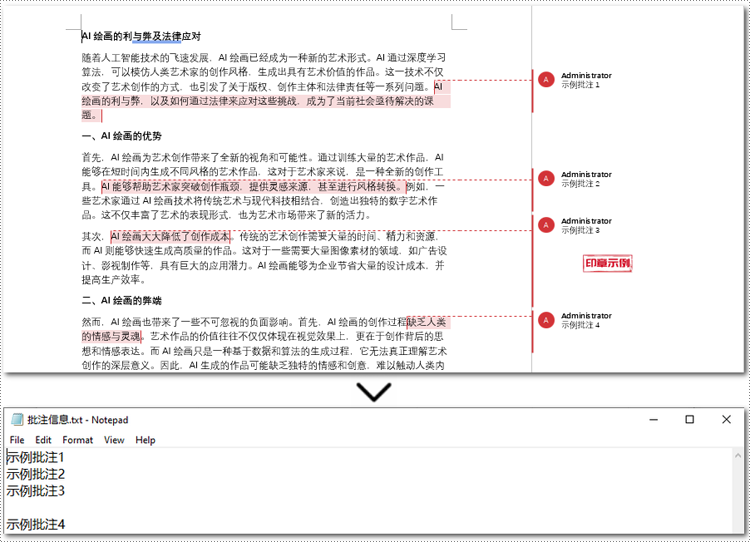
java 提取 word 文档批注中的文本
使用 java 获取 word 文档批注中的文本并不难。首先遍历 word 文档中的所有批注,然后使用 spire.doc for java 提供的 document.getcomments().get() 方法获取当前的批注,再然后遍历批注正文的每一个段落并获取当前段落,最后使用 paragraph.gettext() 方法获取该段落的文本。下面是具体的操作步骤:
- 创建一个 document 类的对象。
- 通过 document.loadfromfile() 方法,加载一个 word 文档。
- 遍历这个文档中的所有批注。
- 对于每条批注,遍历其正文中的所有段落。
- 对于每个段落,使用 paragraph.gettext() 方法提取其文本内容。
- 将提取到的内容保存为文本文件。
- java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.*;
import java.io.*;
public class extractcomments {
public static void main(string[] args) throws ioexception {
// 创建一个 document 类的对象
document doc = new document();
// 加载一个 word 文档
doc.loadfromfile("/ai绘画的利弊及法律应对.docx");
// 遍历文档中的每个批注
for (int i = 0; i < doc.getcomments().getcount(); i ) {
// 获取当前索引处的批注
comment comment = doc.getcomments().get(i);
// 遍历批注正文中的每个段落
for (int j = 0; j < comment.getbody().getparagraphs().getcount(); j ) {
// 获取当前的段落
paragraph para = comment.getbody().getparagraphs().get(j);
// 获取该段落的文本
string result = para.gettext() "\r\n";
// 将提取到的批注保存为文本文件
writestringtotxt(result, "/批注信息.txt");
}
}
// 释放资源
doc.dispose();
}
// 自定义将数据写入到文本文件的方法
public static void writestringtotxt(string content, string txtfilename) throws ioexception {
filewriter fwriter = new filewriter(txtfilename);
try {
// 写入文本文件
fwriter.write(content);
} catch (ioexception ex) {
ex.printstacktrace();
} finally {
try {
// 关闭文件写入器
fwriter.flush();
fwriter.close();
} catch (ioexception ex) {
ex.printstacktrace();
}
}
}
}
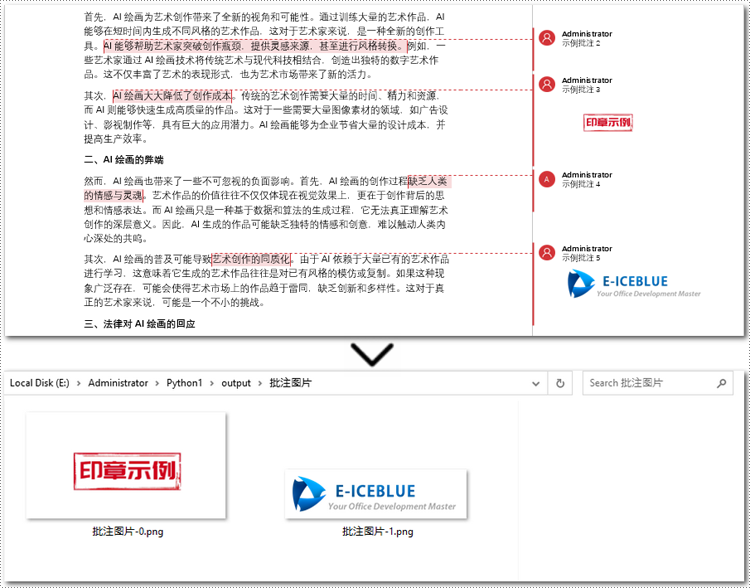
java 提取 word 文档批注中的图片
要从 word 文档的批注中提取图片,需要遍历批注段落中的子对象,找到 docpicture 对象。然后通过 docpicture.getimagebytes() 方法获取图片数据,并将其保存为图像文件。
- 创建一个 document 类的对象。
- 使用 document.loadfromfile() 方法加载一个 word 文档。
- 创建一个列表以储存提取的图片数据。
- 遍历文档中的批注。
- 对每一个批注,遍历其批注正文的每一个段落。
- 对每个段落,遍历该段落的所有子对象。
- 检查该对象是否为 docpicture 类型。
- 如果对象是 docpicture,则使用 docpicture.getimagebytes 属性获取图片数据并将其添加到列表中。
- 将列表中的图片数据保存为图像文件。
- java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.*;
import java.io.*;
import java.nio.file.*;
import java.util.arraylist;
import java.util.list;
public class extractcommentimages {
public static void main(string[] args) {
// 创建一个 document 对象
document document = new document();
// 加载包含批注的 word 文档
document.loadfromfile("/ai绘画的利弊及法律应对.docx");
// 创建一个列表来存储提取的图片数据
list images = new arraylist<>();
// 遍历文档中的批注
for (int i = 0; i < document.getcomments().getcount(); i ) {
comment comment = document.getcomments().get(i);
// 遍历批注正文中的所有段落
for (int j = 0; j < comment.getbody().getparagraphs().getcount(); j ) {
paragraph paragraph = comment.getbody().getparagraphs().get(j);
// 遍历段落中的所有子对象
for (int k = 0; k < paragraph.getchildobjects().getcount(); k ) {
documentobject obj = paragraph.getchildobjects().get(k);
// 检查是否为图片
if (obj instanceof docpicture) {
docpicture picture = (docpicture) obj;
// 获取图片数据并添加到列表
images.add(picture.getimagebytes());
}
}
}
}
// 指定输出路径
string outputdir = "/批注图片/";
new file(outputdir).mkdirs();
// 保存图片数据为文件
for (int i = 0; i < images.size(); i ) {
string filename = string.format("批注图片-.png", i);
path filepath = paths.get(outputdir, filename);
try (fileoutputstream fos = new fileoutputstream(filepath.tofile())) {
fos.write(images.get(i));
} catch (ioexception e) {
e.printstacktrace();
}
}
}
} 
申请临时 license
如果您希望删除结果文档中的评估消息,或者摆脱功能限制,请该email地址已收到反垃圾邮件插件保护。要显示它您需要在浏览器中启用javascript。获取有效期 30 天的临时许可证。


