


pdf 中的图层类似于图像编辑软件中的图层,可以将文档的不同元素组织和管理在一起。每个图层可以包含不同的内容,如文本、图片、图形或注释,并且可以独立地显示或隐藏。pdf 图层通常用于控制文档中特定元素的可见性和位置,以便更容易管理复杂布局、创建动态设计或控制信息的显示。在本文中,您将学习如何使用 spire.pdf for python 在 python 中添加、隐藏和删除 pdf 文档中的图层。
安装 spire.pdf for python
本教程需要用到 spire.pdf for python 和 plum-dispatch v1.7.4。可以通过以下 pip 命令将它们轻松安装到 vs code 中。
pip install spire.pdf如果您不确定如何安装,请参考此教程: 如何在 vs code 中安装 spire.pdf for python
python 在 pdf 中添加图层
使用 document.layers.addlayer() 方法可以向 pdf 文档添加图层。在创建图层对象之后,您可以在其上绘制文本、图片、字段或其他元素来形成其外观。使用 spire.pdf for python 添加图层到 pdf 的详细步骤如下所示。
- 创建一个 pdfdocument 对象。
- 使用 pdfdocument.loadfromfile() 方法加载一个 pdf 文件。
- 使用 document.layers.addlayer() 方法创建一个图层。
- 通过 pdfdocument.pages[index] 属性获取特定页面。
- 使用 pdflayer.creategraphics() 方法基于页面创建一个图层的画布。
- 使用 pdfcanvas.drawstring()方法在画布上绘制文本。
- 使用 pdfdocument.savetofile() 方法将文档保存到另一个 pdf 文件中。
- python
from spire.pdf.common import *
from spire.pdf import *
def addlayerwatermark(pdfdocument):
# 添加一个名为"水印图层"的图层
layer = pdfdocument.layers.addlayer("水印图层")
# 创建字体实例,字体设置为宋体,大小为50.0,加粗
font = pdftruetypefont("宋体", 50.0, 1, true)
# 水印文本内容
watermarktext = "内部使用"
# 测量水印文本在给定字体下的尺寸
fontsize = font.measurestring(watermarktext)
# 获取pdf文档中的总页数
pagecount = pdfdocument.pages.count
# 遍历每一页
for i in range(0, pagecount):
# 获取当前页对象
page = pdfdocument.pages[i]
# 在当前页上创建图形画布
canvas = layer.creategraphics(page.canvas)
# 计算水印文本的横向位置
x = (canvas.size.width - fontsize.width) / 2
# 计算水印文本的纵向位置
y = (canvas.size.height - fontsize.height) / 2
# 在画布上绘制水印文本
canvas.drawstring(watermarktext, font, pdfbrushes.get_red(), x, y )
# 创建一个pdfdocument实例
pdf = pdfdocument()
# 加载输入的pdf文件
pdf.loadfromfile("输入文档.pdf")
# 调用添加水印的函数
addlayerwatermark(pdf)
# 将带有水印的pdf文件保存为新的文件
pdf.savetofile("添加图层.pdf", fileformat.pdf)
pdf.close()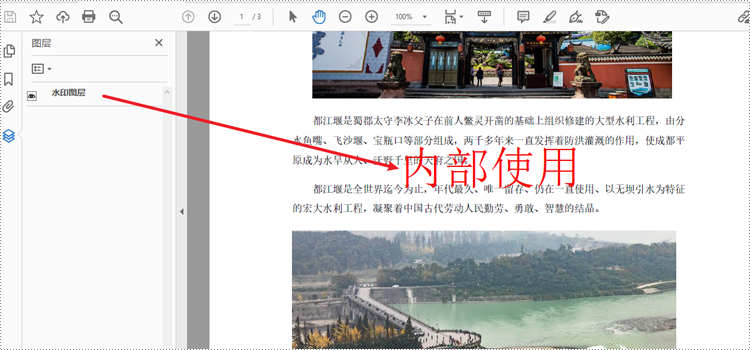
python 设置 pdf 中图层的可见性
要控制 pdf 文档中图层的可见性,您可以使用 pdfdocument.layers[index].visibility 属性。将其设置为 off 以隐藏图层,或将其设置为 on 以取消隐藏图层。具体步骤如下:
- 创建一个 pdfdocument 对象。
- 使用 pdfdocument.loadfromfile() 方法加载一个 pdf 文件。
- 通过 document.layers[index].visibility 属性设置某个图层的可见性。
- 使用 pdfdocument.savetofile() 方法将文档保存到另一个 pdf 文件中。
- python
from spire.pdf.common import *
from spire.pdf import *
# 创建一个pdfdocument实例
pdfdocument = pdfdocument()
# 从文件加载pdf文档
pdfdocument.loadfromfile("图层.pdf")
# 将第一个图层的可见性设置为隐藏
pdfdocument.layers[0].visibility = pdfvisibility.off
# 将隐藏图层后的文档保存为新的pdf文件
pdfdocument.savetofile("隐藏图层.pdf", fileformat.pdf)
pdfdocument.close()python 删除 pdf 中的某一个图层
如果不再需要某个图层,您可以使用 pdfdocument.layers.removelayer() 方法将其移除。以下是详细步骤:
- 创建一个 pdfdocument 对象。
- 使用 pdfdocument.loadfromfile() 方法加载一个pdf文件。
- 通过 pdfdocument.layers[index] 属性获取特定的图层。
- 使用 pdfdocument.layers.removelayer(pdflayer.name) 方法从文档中移除该图层。
- 使用 pdfdocument.savetofile() 方法将文档保存到另一个 pdf 文件中。
- python
from spire.pdf.common import *
from spire.pdf import *
# 创建一个pdfdocument实例
pdfdocument = pdfdocument()
# 从文件加载pdf文档
pdfdocument.loadfromfile("图层.pdf")
# 删除文档中的第一个图层
pdfdocument.layers.removelayer(pdfdocument.layers[0].name)
# 将删除图层后的文档保存为新的pdf文件
pdfdocument.savetofile("删除图层.pdf", fileformat.pdf)
pdfdocument.close()申请临时 license
如果您希望删除结果文档中的评估消息,或者摆脱功能限制,请该email地址已收到反垃圾邮件插件保护。要显示它您需要在浏览器中启用javascript。获取有效期 30 天的临时许可证。


