


使用 python 来操作 pdf 文本的格式,是提高文档处理效率的有效方法。借助 spire.pdf for python 库,开发者可以通过其文本查找功能精确定位文本,轻松获取其格式信息,并对文本的颜色、大小和字体等格式进行修改。这种方式特别适合需要在大量 pdf 文档中统一调整特定文本的格式的场景,不仅节省操作的时间,还能确保格式的一致性。
本文将演示如何使用 spire.pdf for python,通过 python 代码获取并修改 pdf 文档中文本的格式。
安装 spire.pdf for python
本教程需要用到 spire.pdf for python 和 plum-dispatch v1.7.4。可以通过以下 pip 命令将它们轻松安装到 windows 中。
pip install spire.pdf如果您不确定如何安装,请参考:如何在 windows 中安装 spire.pdf for python
在 pdf 中查找文本并获取其字体格式
开发者可以使用 spire.pdf for python 提供的 pdftextfinder 和 pdftextfindoptions 类,在 pdf 文档中精确搜索指定文本,并获取代表搜索结果的 pdftextfragment 对象集合。然后,开发者可以通过 pdftextfragment.textstates[] 属性下的一些属性,访问指定搜索结果文本的格式信息,如字体名称 (fontname)、字体大小 (fontsize) 和字体族 (fontfamily)。
查找 pdf 中的文本并获取其字体信息的详细步骤如下:
- 创建 pdfdocument 类的实例,并使用 pdfdocument.loadfromfile() 方法加载 pdf 文档。
- 使用 pdfdocument.pages.get_item() 方法获取页面。
- 使用获取的页面创建 pdftextfinder 对象。
- 创建 pdftextfindoptions 对象,设置搜索选项,并通过 pdftextfinder.options 属性应用这些选项。
- 使用 pdftextfinder.find() 方法在页面上查找指定文本,获取 pdftextfragment 对象的集合。
- 通过 pdftextfragment.textstates 属性获取第一个搜索结果的格式信息。
- 通过 pdftextstates[0].fontname、pdftextstates[0].fontsize 和 pdftextstates[0].fontfamily 属性,获取该搜索结果的字体名称、字体大小和字体族。
- 输出结果。
- python
from spire.pdf import *
# 创建一个 pdfdocument 实例
pdf = pdfdocument()
# 加载一个pdf文件
pdf.loadfromfile("示例.pdf")
# 获取第一页
page = pdf.pages.get_item(0)
# 创建一个 pdftextfinder 实例
finder = pdftextfinder(page)
# 创建一个 pdftextfindoptions 实例并设置搜索选项
options = pdftextfindoptions()
options.casesensitive = true # 设置为区分大小写
options.wholewords = true # 设置为全词匹配
# 应用这些选项
finder.options = options
# 查找指定文本
fragments = finder.find("云服务器的概念与工作原理")
# 获取第一个片段的格式
formatting = fragments[0].textstates
# 获取格式信息
fontinfo = ""
fontinfo = "文本: " fragments[0].text
fontinfo = "\n字体: " formatting[0].fontname
fontinfo = "\n字体大小: " str(formatting[0].fontsize)
fontinfo = "\n字体族: " formatting[0].fontfamily
# 输出字体信息
print(fontinfo)
# 释放资源
pdf.dispose()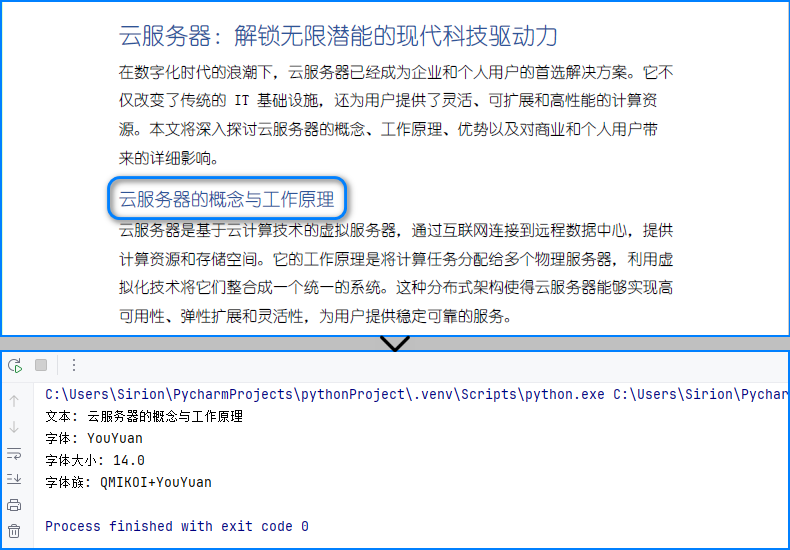
在 pdf 中查找文本并修改其格式
在 pdf 文档中找到指定文本后,开发者还可以在相同的位置上覆盖一个与背景颜色相同的矩形,然后以新的格式重绘文本,从而实现对纯色背景页面上的简单 pdf 文本片段的格式进行修改。具体步骤如下:
- 创建 pdfdocument 类的实例,并使用 pdfdocument.loadfromfile() 方法加载 pdf 文档。
- 通过 pdfdocument.pages.get_item() 方法获取页面。
- 使用页面创建 pdftextfinder 对象。
- 创建 pdftextfindoptions 对象,设置搜索选项,并通过 pdftextfinder.options 属性应用这些选项。
- 使用 pdftextfinder.find() 方法查找页面上的指定文本,并获取第一个结果。
- 通过 pdfpagebase.backgroundcolor 属性获取页面背景颜色,如果背景为空,则将颜色改为白色。
- 使用 pdfpagebase.canvas.drawrectangle() 方法,在找到的文本位置绘制获得的颜色矩形。
- 创建新的字体、画刷和字符串格式,并计算文本位置。
- 使用 pdfpagebase.canvas.drawstring() 方法,在相同位置以新的格式重绘文本。
- 使用 pdfdocument.savetofile() 方法保存文档。
- python
from spire.pdf import *
# 创建一个 pdfdocument 实例
pdf = pdfdocument()
# 从指定路径加载一个pdf文件
pdf.loadfromfile("示例.pdf")
# 获取第一页
page = pdf.pages.get_item(0)
# 创建一个 pdftextfinder 实例
finder = pdftextfinder(page)
# 创建一个 pdftextfindoptions 实例并设置搜索选项
options = pdftextfindoptions()
options.casesensitive = true # 设置为区分大小写
options.wholewords = true # 设置为全词匹配
finder.options = options
# 查找指定文本
text = "云服务器的概念与工作原理"
fragments = finder.find(text)
# 获取第一个结果
fragment = fragments[0]
# 获取页面背景颜色,如果其为空,则将其改为白色
backcolor = page.backgroundcolor
if backcolor.toargb() == 0:
backcolor = color.get_white()
# 使用背景色绘制矩形以覆盖原有文本
for i in range(len(fragment.bounds)):
page.canvas.drawrectangle(pdfsolidbrush(pdfrgbcolor(backcolor)), fragment.bounds[i])
# 创建新的字体和画刷
font = pdftruetypefont("微软雅黑", 13.0, pdffontstyle.italic, true)
brush = pdfbrushes.get_brown()
# 创建一个 pdfstringformat 实例,并设置对齐方式
stringformat = pdfstringformat()
stringformat.alignment = pdftextalignment.left # 左对齐
# 计算包含文本的矩形区域
point = fragment.bounds[0].location # 文本框起始位置
size = sizef(fragment.bounds[-1].right, fragment.bounds[-1].bottom) # 文本框大小
rect = rectanglef(point, size) # 定义文本框矩形
# 在同一矩形区域内用指定格式绘制新文本
page.canvas.drawstring(text, font, brush, rect, stringformat)
# 保存文档到输出文件
pdf.savetofile("output/查找修改pdf文本格式.pdf")
# 释放资源
pdf.close()
申请临时 license
如果您希望删除结果文档中的评估消息,或者摆脱功能限制,请该email地址已收到反垃圾邮件插件保护。要显示它您需要在浏览器中启用javascript。获取有效期 30 天的临时许可证。


