


透视表是 excel 中强大的数据分析工具,它提供了一种灵活的方式来组织、操作和汇总数据,使用户能在不同角度上查看和比较数据,深入研究数据之间的关系和模式。通过透视表,您可以根据不同的标准(如类别、日期或数值)轻松重新排列和汇总数据。当处理复杂数据集时,您可以将不同的数据集放置在透视表中进行比较以便快速地分析并找出差异和优劣势。因此,透视表这个功能在各领域和行业都有广泛的应用。本文将介绍如何使用 spire.xls for python 在 excel 文档中创建或操作透视表。
安装 spire.xls for python
本教程需要 spire.xls for python 和 plum-dispatch v1.7.4。您可以通过以下 pip 命令将它们轻松安装到 windows 中。
pip install spire.xls如果您不确定如何安装,请参考此教程: 如何在 windows 中安装 spire.xls for python
python 在 excel 中创建透视表
要在 excel 中创建透视表,请按照以下步骤操作:
- 创建一个 workbook 对象。
- 使用 workbook.loadfromfile() 方法加载一个现有的 excel 文档。
- 通过 workbook.worksheets[index] 属性获取指定的工作表。
- 使用 worksheet.range 属性指定透视表的单元格数据范围。
- 使用 workbook.pivotcaches.add() 方法创建 pivotcache 对象。
- 使用 worksheet.pivottables.add() 方法根据 pivotcache 创建透视表。
- 添加行字段。
- 添加值字段。
- 使用 pivottable.pivotbuiltinstyles 设置内置样式到透视表。
- 使用 workbook.savetofile() 方法保存结果文档。
- 使用 workbook.dispose() 方法释放文档对象。
- python
from spire.xls import *
from spire.xls.common import *
# 创建一个workbook对象
workbook = workbook()
# 加载原excel文档
workbook.loadfromfile("data.xlsx")
# 获取第一个工作表
sheet = workbook.worksheets[0]
# 指定透视表的数据范围
cellrange = sheet.range["a1:c15"]
# 添加cellrange到pivotcaches
pivotcache = workbook.pivotcaches.add(cellrange)
# 通过pivotcaches添加透视表并设置位置
pivottable = sheet.pivottables.add("pivot table", sheet.range["e1"], pivotcache)
# 设置透视表的行字段
regionfield = pivottable.pivotfields["continent"]
regionfield.axis = axistypes.row
pivottable.options.rowheadercaption = "continent"
productfield = pivottable.pivotfields["country"]
productfield.axis = axistypes.row
# 添加值字段
pivottable.datafields.add(pivottable.pivotfields["population"], "sum of population", subtotaltypes.sum)
# 设置透视表的样式
pivottable.builtinstyle = pivotbuiltinstyles.pivotstylemedium11
# 设置透视表相应列的列宽
h = sheet.range["e1"]
sheet.setcolumnwidth(h.column, 18)
sheet.setcolumnwidth(h.column 1, 20)
# 保存文件
workbook.savetofile("结果.xlsx", excelversion.version2016)
# 释放对象
workbook.dispose()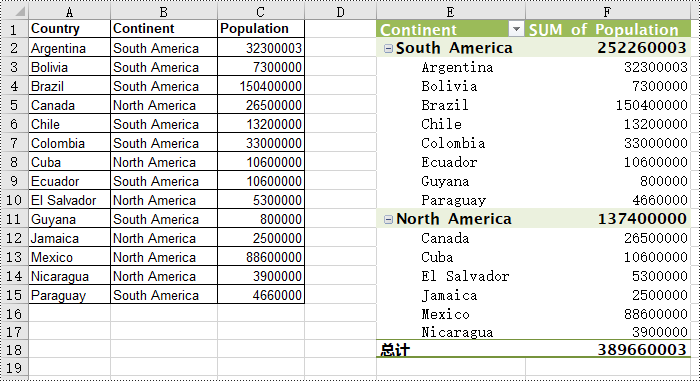
python 按列值对透视表进行排序
在 python 中,可以通过列值对透视表进行排序。 首先,通过 pivottable.pivotfields["fieldname"] 属性访问特定字段,然后使用 pivotfield.sorttype 属性设置其排序类型。以下是按照特定字段的值对透视表进行排序的步骤:
- 创建一个 workbook 对象。
- 使用 workbook.loadfromfile() 方法加载含有透视表的原 excel 文档。
- 通过 workbook.worksheets[index] 属性获取特定的工作表。
- 通过 worksheet.pivottables[index] 属性从工作表中获取特定的透视表。
- 通过 pivottable.pivotfields["fieldname"] 属性获取特定的字段。
- 通过 pivotfield.sorttype 属性对该字段中的数据进行排序。
- 使用 workbook.savetofile() 方法保存结果文件。
- 使用 workbook.dispose() 方法释放文档对象
- python
from spire.xls import *
from spire.xls.common import *
# 创建一个workbook对象
workbook = workbook()
# 加载含有透视表的原excel文档
workbook.loadfromfile("透视表.xlsx")
# 获取第一个工作表
sheet = workbook.worksheets[0]
# 获取第一个透视表
pivottable = sheet.pivottables[0]
# 获取要排序的字段
idfield = pivottable.pivotfields["continent"]
# 按升序排列
idfield.sorttype = pivotfieldsorttype.ascending
# 保存文件
workbook.savetofile("结果.xlsx", excelversion.version2016)
# 释放对象
workbook.dispose()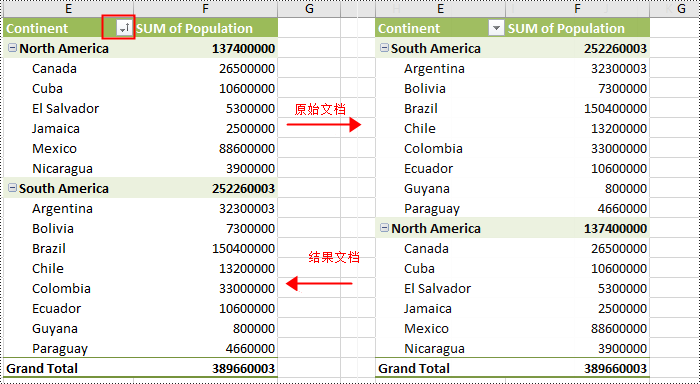
python 展开或折叠透视表中的行
在 python 中展开或折叠数据透视表中的行,使用 pivotfield.hideitemdetail(string itemvalue, bool ishiddendetail) 方法,将第二个参数设置为 true,为折叠效果;设置为 false,为展开效果。详细步骤如下:
- 创建一个 workbook 对象。
- 使用 workbook.loadfromfile() 方法加载含有透视表的原 excel 文档。
- 通过 workbook.worksheets[index] 属性获取特定的工作表。
- 通过 worksheet.pivottables[index] 属性从工作表中获取特定的透视表。
- 通过 pivottable.pivotfields["fieldname"] 属性获取特定的字段。
- 通过 pivotfield.hideitemdetail(string itemvalue, bool ishiddendetail) 方法针对具体项折叠或展开。
- 使用 workbook.savetofile() 方法保存结果文件。
- 使用 workbook.dispose() 方法释放文档对象
- python
from spire.xls import *
from spire.xls.common import *
# 创建一个workbook对象
workbook = workbook()
# 加载含有透视表的原excel文档
workbook.loadfromfile("透视表.xlsx")
# 获取第一个工作表
sheet = workbook.worksheets[0]
# 获取第一个透视表
pivottable = sheet.pivottables[0]
# 获取特定字段
idfield = pivottable.pivotfields["continent"]
# 设置展开或折叠
idfield.hideitemdetail("south america", true)
idfield.hideitemdetail("north america", false)
# 保存文件
workbook.savetofile("结果.xlsx", excelversion.version2016)
# 释放对象
workbook.dispose()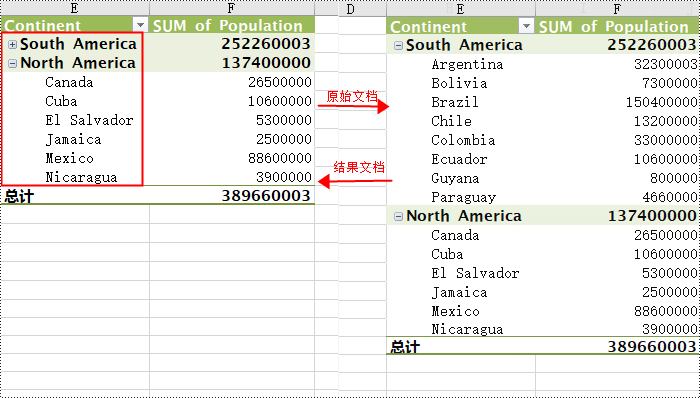
申请临时 license
如果您希望删除结果文档中的评估消息,或者摆脱功能限制,请该email地址已收到反垃圾邮件插件保护。要显示它您需要在浏览器中启用javascript。获取有效期 30 天的临时许可证。


