


通过将大型 pdf 文件拆分为多个较小的 pdf 文件,可以显著减小文件尺寸,从而提升文件管理效率,加快文件打开和处理速度,尤其是在共享或上传时。本文将介绍如何使用 在 python 中实现拆分 pdf 文件的方法。
安装 spire.pdf for python
本教程需要 spire.pdf for python 和 plum-dispatch v1.7.4。您可以通过以下 pip 命令将它们轻松安装到 vs code 中。
pip install spire.pdf如果您不确定如何安装,请参考此教程: 如何在 vs code 中安装 spire.pdf for python
python 将 pdf 文件拆分为多个单页 pdf 文件
spire.pdf for python 提供了一个名为 pdfdocument.split() 的方法,用于将包含多页内容的 pdf 文档分割成多个各自仅含单页内容的 pdf 文件。以下是拆分的详细步骤:
- 创建一个 pdfdocument 类的实例。
- 使用 pdfdocument.loadfromfile() 方法加载 pdf 文档。
- 使用 pdfdocument.split() 方法进行拆分。
- python
from spire.pdf.common import *
from spire.pdf import *
# 创建一个 pdfdocument 对象
doc = pdfdocument()
# 加载一个 pdf 文件
doc.loadfromfile("示例.pdf")
# 将 pdf 文件拆分为多个单页的 pdf 文件
doc.split("输出/拆分结果-{0}.pdf", 1)
# 关闭 pdfdocument 对象
doc.close()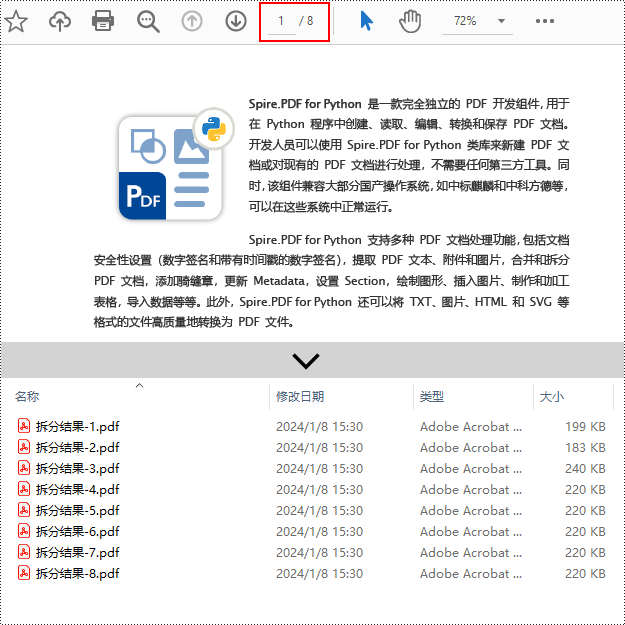
python 按照页面范围拆分 pdf 文件
要将一个 pdf 文件按页码范围拆分为两个或多个 pdf 文件,您需要创建两个或多个新的 pdf 文件,然后通过 insertpage() 以及 insertpagerange() 方法从源 pdf 中导出指定的页面或页码范围到新创建的 pdf 文件中。以下是详细的步骤:
- 创建一个 pdfdocument 对象。
- 使用 pdfdocument.loadfromfile() 方法加载一个 pdf 文档。
- 创建三个 pdfdocument 对象。
- 使用 pdfdocument.insertpage() 方法将源文件的第一页导出到第一个文档中。
- 使用 pdfdocument.insertpagerange() 方法将源文件的第 2-4 页导出到第二个文档中。
- 使用 pdfdocument.insertpagerange() 方法将源文件的剩余页导出到第三个文档中。
- 使用 pdfdocument.savetofile() 方法保存这三个文档。
- python
from spire.pdf.common import *
from spire.pdf import *
# 创建一个 pdfdocument 对象
doc = pdfdocument()
# 加载一个 pdf 文件
doc.loadfromfile("示例.pdf")
# 创建三个 pdfdocument 对象
newdoc_1 = pdfdocument()
newdoc_2 = pdfdocument()
newdoc_3 = pdfdocument()
# 将源文件的第一页插入到第一个文档中
newdoc_1.insertpage(doc, 0)
# 将源文件的第2-4页插入到第二个文档中
newdoc_2.insertpagerange(doc, 1, 3)
# 将源文件的剩余页插入到第三个文档中
newdoc_3.insertpagerange(doc, 4, doc.pages.count - 1)
# 保存这三个文档
newdoc_1.savetofile("输出/拆分结果-1.pdf")
newdoc_2.savetofile("输出/拆分结果-2.pdf")
newdoc_3.savetofile("输出/拆分结果-3.pdf")
# 关闭 pdfdocument 对象
doc.close()
newdoc_1.close()
newdoc_2.close()
newdoc_3.close()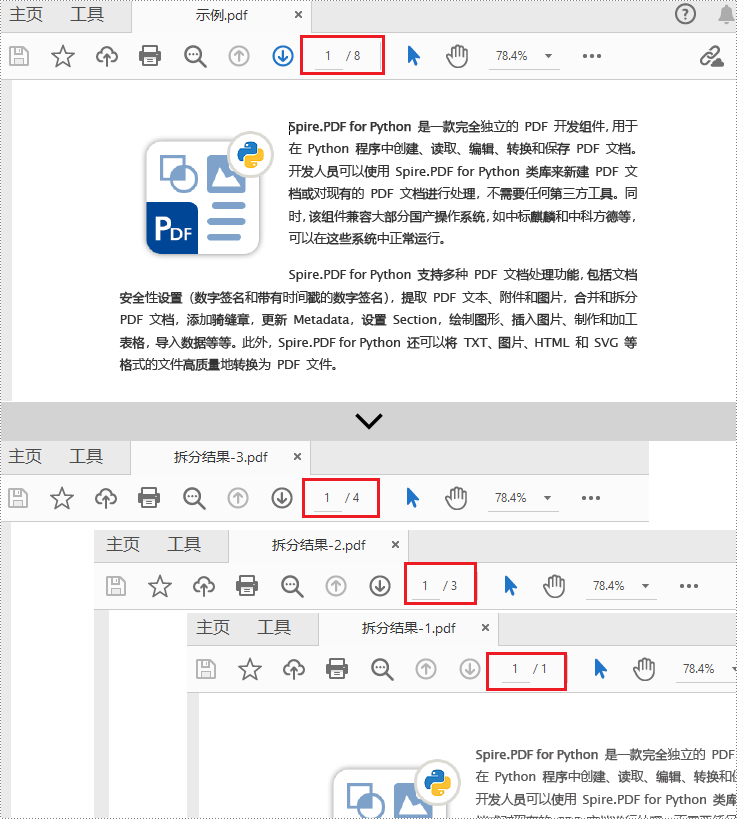
申请临时 license
如果您希望删除结果文档中的评估消息,或者摆脱功能限制,请该email地址已收到反垃圾邮件插件保护。要显示它您需要在浏览器中启用javascript。获取有效期 30 天的临时许可证。


