


从图片中提取文本是光学字符识别(ocr)技术的核心应用,旨在将图片中的文字内容转化为可编辑、可搜索的数字化文本。这项技术广泛应用于文档数字化、信息归档和数据采集等领域,帮助用户高效地从扫描件、照片或其他图片文件中提取文字信息。通过先进的算法和模型,ocr技术能够识别多种字体、语言和复杂的文本布局,显著提升信息处理的效率和准确性,并为智能化数据管理和自动化工作流程提供强有力的支持。本文将介绍如何在 python 应用程序中使用 spire.ocr for python 提取或识别图片中的文字。
安装spire.ocr for python
本教程需要用到 spire.ocr for python 和 plum-dispatch v1.7.4。可以通过以下 pip 命令将它们轻松安装到 windows 中。
pip install spire.ocr下载 spire.ocr for python 模型
spire.ocr for python 为不同的操作系统提供了不同的识别模型。请从以下链接下载适合你的操作系统的模型:
之后,解压下载的压缩包并保存到计算机上的特定目录下。
python 从图片中提取文字
spire.ocr for python 提供了 ocrscanner.scan() 方法从图片中识别文本。识别后,你可以使用 ocrscanner.text 属性获取识别出的文本。具体步骤如下:
- 创建 ocrscanner 类的实例。
- 创建 configureoptions 类的实例。
- 使用 configureoptions.modelpath 和 configureoptions.language 属性设置模型的路径和识别语言。
- 使用 ocrscanner.configuredependencies 属性将设置应用到 ocrscanner 实例。
- 使用 ocrscanner.scan() 方法从图片中识别文本。
- 使用 ocrscanner.text 属性从 ocrscanner 对象中获取识别的文本。
- 将文本保存到文本文件。
- python
from spire.ocr import *
# 创建ocrscanner实例,负责进行图片的ocr扫描和文字识别
scanner = ocrscanner()
# 创建configureoptions实例,用于设置ocr扫描的配置选项
configureoptions = configureoptions()
# 设置ocr模型的路径,指向本地的模型文件夹
configureoptions.modelpath = r'd:\ocr\win-x64'
# 设置文本识别语言为中文
configureoptions.language = 'chinese'
# 将配置选项应用到ocrscanner实例
scanner.configuredependencies(configureoptions)
# 执行ocr扫描,从指定图片文件中识别文本
scanner.scan(r'示例.png')
# 获取ocr识别的文字内容,并将其转换为字符串
text = scanner.text.tostring() '\n'
# 将识别的文字内容写入文本文件(以追加模式打开)
with open('输出.txt', 'a', encoding='utf-8') as file:
file.write(text '\n')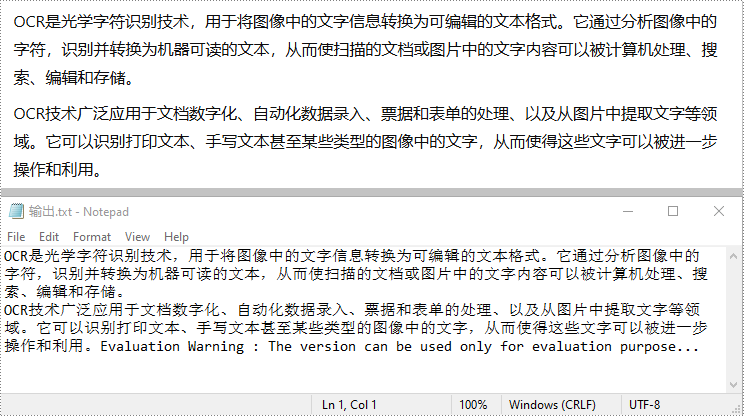
python 从图片中提取文字及其坐标位置
当你需要了解图片中特定文本元素的确切位置时,提取坐标非常有用。使用 spire.ocr for python,你可以按块检索已识别的文本。对于每个文本块,你可以获取其详细位置信息,包括 x 和 y 坐标以及其宽度和高度。具体步骤如下:
- 创建 ocrscanner 类的实例。
- 创建 configureoptions 类的实例。
- 使用 configureoptions.modelpath 和 configureoptions.language 属性设置模型的路径和识别语言。
- 使用 ocrscanner.configuredependencies 属性将设置应用到 ocrscanner 实例。
- 使用 ocrscanner.scan() 方法从图片中识别文本。
- 使用 ocrscanner.text 属性从 ocrscanner 对象获取识别的文本。
- 遍历识别的文本中的文本块。
- 对于每个文本块,使用 iocrtextblock.text 和 iocrtextblock.box.x,iocrtextblock.box.y,iocrtextblock.box.width,iocrtextblock.box.height 属性获取其文本和 x/y 坐标以及宽度和高度。
- 将获取结果保存到文本文件。
- python
from spire.ocr import *
# 创建ocrscanner实例,用于扫描和识别图片中的文本
scanner = ocrscanner()
# 创建configureoptions实例,用于配置ocr扫描的相关选项
configureoptions = configureoptions()
# 设置ocr模型的路径
configureoptions.modelpath = r'd:\ocr\win-x64'
# 设置文本识别语言为中文
configureoptions.language = 'chinese'
# 应用配置选项到ocrscanner实例
scanner.configuredependencies(configureoptions)
# 执行文本识别,扫描指定图片文件
scanner.scan(r'示例.png')
# 获取识别到的文本内容
text = scanner.text
# 初始化空字符串,用于存储每个文本块的文字和位置信息
block_text = ""
# 遍历识别到的文本中的文本块
for block in text.blocks:
# 获取当前文本块的矩形区域
rectangle = block.box
# 获取文本块的文本内容和x/y坐标以及宽度和高度信息
block_info = f'{block.text} -> x: {rectangle.x}, y: {rectangle.y}, w: {rectangle.width}, h: {rectangle.height}'
# 将每个文本块的信息追加到block_text中
block_text = block_info '\n'
# 将识别结果保存到文本文件
with open('输出.txt', 'a', encoding='utf-8') as file:
file.write(block_text '\n')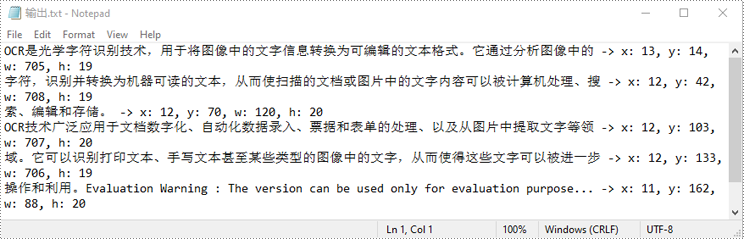
申请临时 license
如果您希望删除结果文档中的评估消息,或者摆脱功能限制,请该email地址已收到反垃圾邮件插件保护。要显示它您需要在浏览器中启用javascript。获取有效期 30 天的临时许可证。


