


在 pdf 文档中,除了使用文本和图像构成文档基本内容外,用户还可以在其中嵌入各种类型的附件,如文档、图像、音频文件或其他多媒体元素。许多 pdf 文档会嵌入附件作为补充资料,如报告、电子表格或法律文件。将这些文档中的附件提取出来,可以方便用户对附件进行检索、修改和分享等操作。本文将演示如何使用 spire.pdf for python 通过 python 程序从 pdf 文档中提取附件。
安装 spire.pdf for python
本教程需要用到 spire.pdf for python 和 plum-dispatch v1.7.4。可以通过以下 pip 命令将它们轻松安装到 vs code 中。
pip install spire.pdf如果您不确定如何安装,请参考:如何在 vs code 中安装 spire.pdf for python
相关知识
pdf 文件中有两类附件:文档级附件和注释级附件。下面的表格说明了这两类附件之间的差异以及它们在 spire.pdf 中的表示方式。
| 附件类型 | 表示方式 | 定义 |
| 文档附件 | pdfattachment 类 | 以文档级添加的 pdf 附件不会显示在 pdf 页面上,但可以在 pdf 阅读器的“附件”面板中查看。 |
| 注释附件 | pdfannotationattachment 类 | 作为注释附加的文件可以在页面上或“附件”面板中找到。注释附件在页面上显示为一个纸夹图标;阅读文档时可以双击该图标打开文件。 |
用 python 从 pdf 中提取文档附件
使用 pdfdocument.attachments 属性可以获取 pdf 文档中的文档附件。每个附件都有一个 pdfattachment.filename 属性,提供指定附件的文件名(包括文件扩展名)。此外,pdfattachment.data 属性能帮助开发者访问附件的数据,pdfattachment.data.save() 方法将附件保存到指定文件夹。
使用 python 从 pdf 中提取文档附件的操作步骤如下:
- 创建一个 pdfdocument 类的对象。
- 使用 pdfdocument.loadfromfile() 方法加载 pdf 文件。
- 使用 pdfdocument.attachments 属性获取附件的集合。
- 遍历附件集合。
- 从集合中获取指定附件,并使用 pdfattachment.filename 属性和 pdfattachment.data 属性获取附件的文件名和文件数据。
- 使用 pdfattachment.data.save() 方法将附件保存到指定的文件夹中。
- python
from spire.pdf import *
from spire.pdf.common import *
# 创建pdfdocument类的对象
doc = pdfdocument()
# 载入pdf文件
doc.loadfromfile("示例.pdf")
# 获取文档中的文档附件集合
collection = doc.attachments
# 遍历附件集合
if collection.count > 0:
for i in range(collection.count):
# 获取指定附件
attactment = collection.get_item(i)
# 获取附件的文件名和文件数据
filename= attactment.filename
data = attactment.data
# 保存附件到指定文件夹
data.save("output/文档附件/" filename)
doc.close()
用 python 从 pdf 中提取注释附件
注释附件是基于页面的元素。要从特定页面获取注释附件,可以先通过 pdfpagebase.annotationswidget 属性获取页面注释,然后判断注释是否是附件注释,最后将附件注释中的附件保存到指定的文件夹即可。
以下是使用 python 从 pdf 中提取注释附件的操作步骤:
- 创建一个 pdfdocument 类的对象。
- 使用 pdfdocument.loadfromfile() 方法加载 pdf 文件。
- 遍历文档中的页面。
- 通过 pdfpagebase.annotationswidget 属性获取指定页面的所有注释。
- 遍历注释,并确定指定注释是否是附件注释。
- 如果是附件注释,则使用 pdfattachmentannotation.filename 属性和 pdfattachmentannotation.data 属性获取附件的文件名和文件数据。
- 将注释附件保存到指定的文件夹中。
- python
from spire.pdf import *
from spire.pdf.common import *
# 创建pdfdocument类的对象
doc = pdfdocument()
# 载入pdf文件
doc.loadfromfile("示例1.pdf")
# 遍历文档页面
for i in range(doc.pages.count):
# 获取指定页面
page = doc.pages.get_item(i)
# 获取页面上的所有注释
annotationcollection = page.annotationswidget
# 判断页面是否包含注释
if annotationcollection.count > 0:
# 遍历页面中的注释
for j in range(annotationcollection.count):
# 获取指定注释
annotation = annotationcollection.get_item(j)
# 判断指定注释是否为附件注释
if isinstance(annotation, pdfattachmentannotationwidget):
# 获取附件的文件名和文件数据
filename = annotation.filename
bytedata = annotation.data
streamms = stream(bytedata)
# 将附件保存到指定文件夹
streamms.save("output/注释附件/" filename)
doc.close()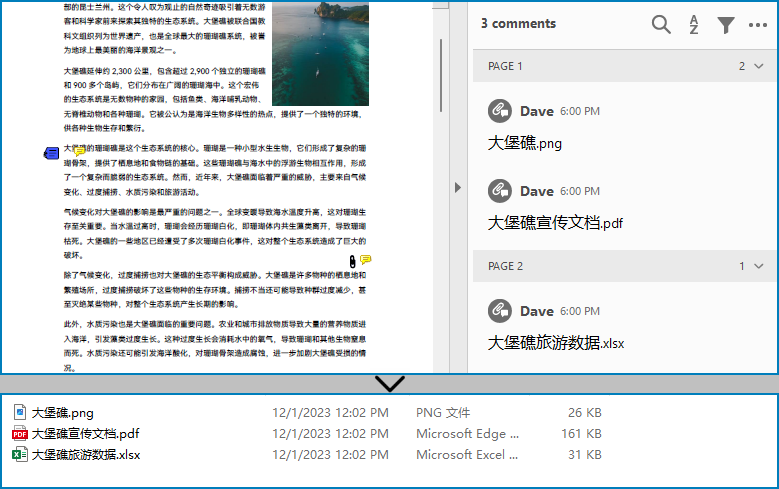
申请临时 license
如果您希望删除结果文档中的评估消息,或者摆脱功能限制,请该email地址已收到反垃圾邮件插件保护。要显示它您需要在浏览器中启用javascript。获取有效期 30 天的临时许可证。


