


在 word 中,书签是一种文档浏览与定位的重要工具,在文档编辑软件中发挥着关键作用。它可以帮助我们快速定位到重要的段落处,从而获取段落内容;它也经常会起到占位符的作用,有了它,我们可以将数据插入到文档中任意的位置。在这篇文章中,我们将探讨如何使用 spire.doc for python 替换或获取 word 书签内容。
安装 spire.doc for python
本教程需要 spire.doc for python 和 plum-dispatch v1.7.4。您可以通过以下 pip 命令将它们轻松安装到 windows 中。
pip install spire.doc如果您不确定如何安装,请参考此教程: 如何在 windows 中安装 spire.doc for python
用于测试的 word 源文档如下图:
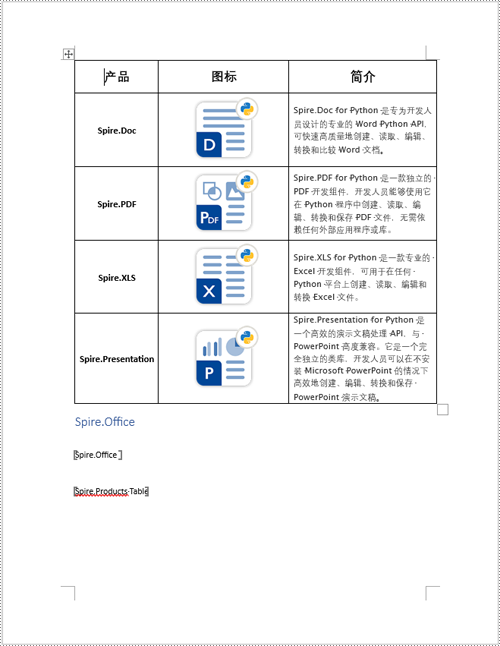
python 替换 word 书签内容
书签替换内容分为两种,文本和其他内容(如图片、表格或 officemath 公式等其他对象)。首先都需要定位到书签,定位后,文本内容可以使用字符串直接进行替换,其他对象的话则需要添加进 textbodypart 对象中再进行替换。这里以表格为例,详细步骤如下:
- 创建一个 document 对象,并通过 document.loadfromfile() 加载文档。
- 创建书签定位器对象 bookmarksnavigator 后使用 bookmarksnavigator.movetobookmark() 方法通过书签名字定位书签
- 使用 bookmarksnavigato.replacebookmarkcontent(str,bool) 替换书签文本
- 参照第二步定位到另一个书签
- 使用 document.sections.get_item(0).tables.get_item(0) 获取表格
- 创建 textbodypart 对象,并使用 textbodypart.bodyitems.add() 方法将表格添加进去
- 使用 bookmarksnavigato.replacebookmarkcontent(textbodypart,bool,bool) 替换书签内容
- python
from spire.doc import *
# 创建document对象并加载文档
document = document()
document.loadfromfile("d:\\schedule\\data\\模板.docx")
# 创建书签定位器对象并根据书签名字定位书签
bookmarknavigator_office = bookmarksnavigator(document)
bookmarknavigator_office.movetobookmark("spire_office")
# 用文本替换书签,true代表保留格式
bookmarknavigator_office.replacebookmarkcontent(
"spire.office for python 是一个功能强大的综合类库,帮助开发人员使用 python编程语言处理各种文件格式的文档。" \
"spire.office for python 包括 spire.doc for python,spire.xls for python,spire.presentation for python 和 spire.pdf for python。\n"
"通过使用 spire.office for python,开发人员可以处理 word (doc、docx)、excel (xls、xlsx)、powerpoint (ppt、pptx)、pdf " \
"和其他多种文档格式。该库提供了广泛、高效的文档处理功能,可用于执行文档的读取、创建、编辑和转换等多种任务",
true)
# 创建书签定位器对象并根据书签名字定位书签
bookmarknavigator_products = bookmarksnavigator(document)
bookmarknavigator_products.movetobookmark("spire_products")
# 获取第一个表格
table = document.sections.get_item(0).tables.get_item(0)
# 创建textbodypart对象,并把table对象添加进去
textbodypart = textbodypart(document)
textbodypart.bodyitems.add(table)
# 用textbodypart替换书签内容,第一个true代表保留第一段的格式,第二个true代表保留替换内容的格式
bookmarknavigator_products.replacebookmarkcontent(textbodypart, true, true)
# 保存文档
document.savetofile("模板_output.docx", fileformat.docx)
document.close()
document.dispose()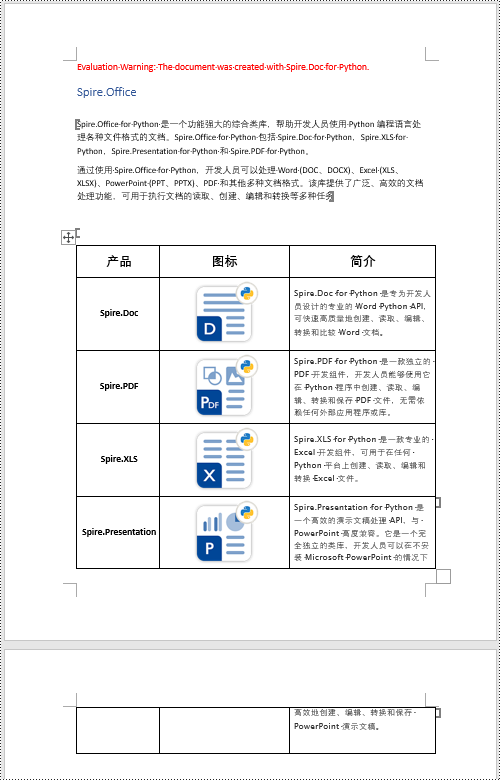
python 获取 word 书签内容
以上例的结果文件测试,获取第一个书签内的文本内容,详细步骤如下:
- 创建一个 document 对象。
- 使用 document.loadfromfile() 方法加载 word 文件。
- 创建 bookmarksnavigator 对象,并使用 bookmarksnavigator.movetobookmark() 定位书签
- 使用 bookmarksnavigator.getbookmarkcontent() 获取该书签内容的集合
- 遍历书签内容集合的子对象,并判断是否为 paragraph 对象,若是则强转为 paragraph 对象
- 继续遍历 paragraph 中的子对象,并判断是否为 textrange 文本对象,若是则强转为 textrange 对象,并使用 textrange.text 写入字符串。
- 遍历结束后,使用 with fileio(outputfile, mode="w") as 以写模式创建文件对象,并将字符串内容写入指定文本文件中。
- python
from spire.doc import *
from io import fileio
# 创建document对象,并加载输入文件
doc = document()
doc.loadfromfile("模板_output.docx")
# 创建书签导航器,并定位到书签
navigator = bookmarksnavigator(doc)
navigator.movetobookmark("spire_office")
# 获取书签内容的集合
textbodypart = navigator.getbookmarkcontent()
text = ''
# 遍历集合中的子对象
for i in range(textbodypart.bodyitems.count):
item = textbodypart.bodyitems.get_item(i)
# 如果子对象为段落则继续遍历段落子对象集合
if isinstance(item, paragraph):
for j in range((item if isinstance(item, paragraph) else
none).childobjects.count):
# 获取段落子对象
childobject = (item if isinstance(item, paragraph) else
none).childobjects.get_item(j)
# 判断若是textrange类型,则写入text字符串中
if isinstance(childobject, textrange):
text = (childobject
if isinstance(childobject, textrange) else none).text
# 指定输出文件,并创建文件对象输出text到指定文件
outputfile = "extractbookmarktext.txt"
with fileio(outputfile, mode="w") as f:
f.write(text.encode("utf-8"))
doc.close()
doc.dispose()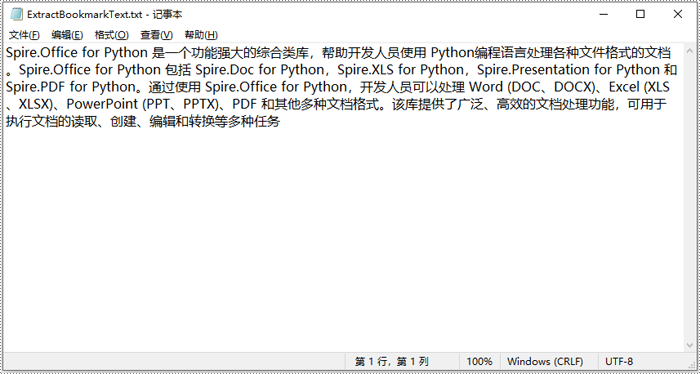
申请临时 license
如果您希望删除结果文档中的评估消息,或者摆脱功能限制,请该email地址已收到反垃圾邮件插件保护。要显示它您需要在浏览器中启用javascript。获取有效期 30 天的临时许可证。


