


许多财务和会计文件,如财务报表、预算报告和交易清单等,广泛以 pdf 格式存储。这些 文件通常包含大量有价值的表格数据。通过提取这些表格数据,我们能够便捷地对其进行统计分析,并生成详尽的报告。这篇文章将介绍如何使用 spire.pdf for python 和 spire.xls for python 提取 pdf 文档中的表格数据。
安装 spire.pdf for python 和 spire.xls for python
本教程需要用到 spire.pdf for python 和 spire.xls for python。spire.pdf for python 用于从 pdf 表格中提取数据,spire.xls for python 用于将提取的表格数据写入到 excel 表格。
您可以通过以下 pip 命令将它轻松安装到 windows 中:
pip install spire.pdf
pip install spire.xls如果您不清楚如何安装,请参考:
python 提取 pdf 表格数据并保存到文本文件
spire.pdf for python 提供了 pdftableextractor.extracttable(pageindex) 方法,支持从 pdf 文档页面中获取表格。获取后,遍历表格中的行和列并使用 pdftable.gettext(rowindex, columnindex) 方法即可获取每个表格单元格中的文本。具体步骤如下:
- 创建 pdfdocument 类的实例。
- 使用 pdfdocument.loadfromfile() 方法加载 pdf 文档。
- 遍历 pdf 文档中的页面。
- 使用 pdftableextractor.extracttable() 方法获取页面中的表格。
- 遍历提取的表格。
- 使用 pdftable.gettext() 方法获取表格单元格中的文本并保存到列表中。
- 将列表的内容写入 .txt 文件。
- python
from spire.pdf.common import *
from spire.pdf import *
# 创建pdfdocument对象
doc = pdfdocument()
# 加载pdf文件
doc.loadfromfile("示例.pdf")
# 创建用于存储表格数据的列表
builder = []
# 创建pdftableextractor对象
extractor = pdftableextractor(doc)
# 遍历pdf文件中的页面
for pageindex in range(doc.pages.count):
# 从当前页面中提取表格
tablelist = extractor.extracttable(pageindex)
# 遍历表格
if tablelist is not none and len(tablelist) > 0:
for table in tablelist:
# 获取当前表格的行数和列数
row = table.getrowcount()
column = table.getcolumncount()
# 遍历表格的行和列
for i in range(row):
for j in range(column):
# 获取当前单元格中的文本
text = table.gettext(i, j)
# 将文本添加到列表
builder.append(text " ")
builder.append("\n")
builder.append("\n")
# 将列表的内容保存到文本文件中
with open("表格.txt", "w", encoding="utf-8") as file:
file.write("".join(builder))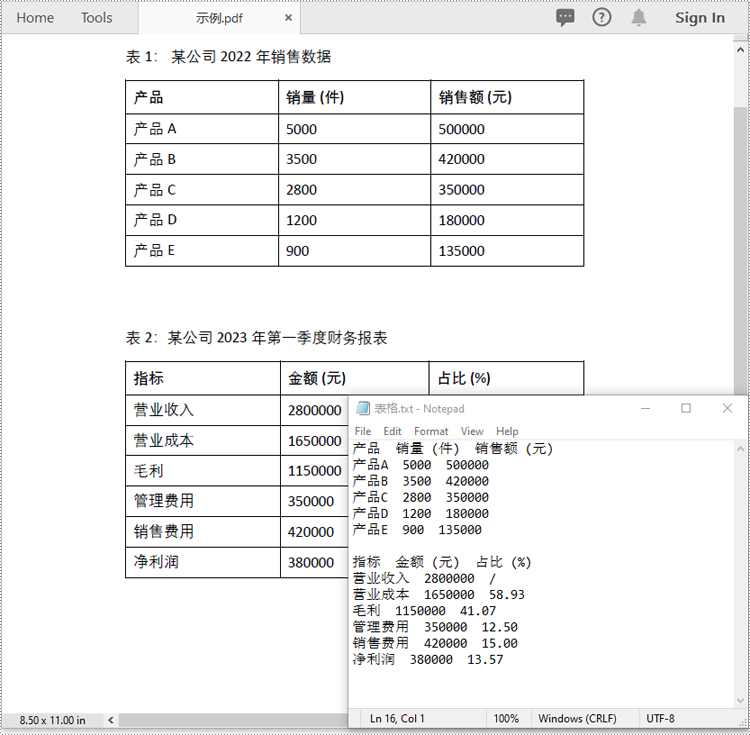
python 提取 pdf 表格数据并保存到 excel 表格
获取表格单元格的文本后,你可以使用 spire.xls for python 提供的 worksheet.range[rowindex, columnindex].value 属性将其写入 excel 工作表。具体步骤如下:
- 创建 pdfdocument 类的实例。
- 使用 pdfdocument.loadfromfile() 方法加载示例 pdf 文档。
- 创建 workbook 类的实例并清除其中默认的工作表。
- 遍历 pdf 文档中的页面。
- 使用 pdftableextractor.extracttable() 方法提取页面中的表格。
- 遍历提取的表格。
- 对于每个表格,使用 workbook.worksheets.add() 方法向工作簿中添加一个工作表。
- 使用 pdftable.gettext() 方法获取表格单元格中的文本。
- 使用 worksheet.range[rowindex, columnindex].value 属性将文本写入工作表的特定单元格。
- 使用 workbook.savetofile() 方法将结果工作簿保存到 excel 文件。
- python
from spire.pdf import *
from spire.xls import *
# 创建pdfdocument对象
doc = pdfdocument()
# 加载pdf文件
doc.loadfromfile("示例.pdf")
# 创建workbook对象
workbook = workbook()
# 清除默认工作表
workbook.worksheets.clear()
# 创建pdftableextractor对象
extractor = pdftableextractor(doc)
sheetnumber = 1
# 遍历pdf文件中的页面
for pageindex in range(doc.pages.count):
# 从当前页面提取表格
tablelist = extractor.extracttable(pageindex)
# 遍历表格
if tablelist is not none and len(tablelist) > 0:
for table in tablelist:
# 为当前表格添加一个工作表
sheet = workbook.worksheets.add(f"sheet{sheetnumber}")
# 获取表格的行数和列数
row = table.getrowcount()
column = table.getcolumncount()
# 遍历表格的行和列
for i in range(row):
for j in range(column):
# 获取当前单元格中的文本
text = table.gettext(i, j)
# 将文本写入工作表的指定单元格
sheet.range[i 1, j 1].value = text
sheetnumber = 1
# 将工作簿保存为excel文件
workbook.savetofile("表格.xlsx", 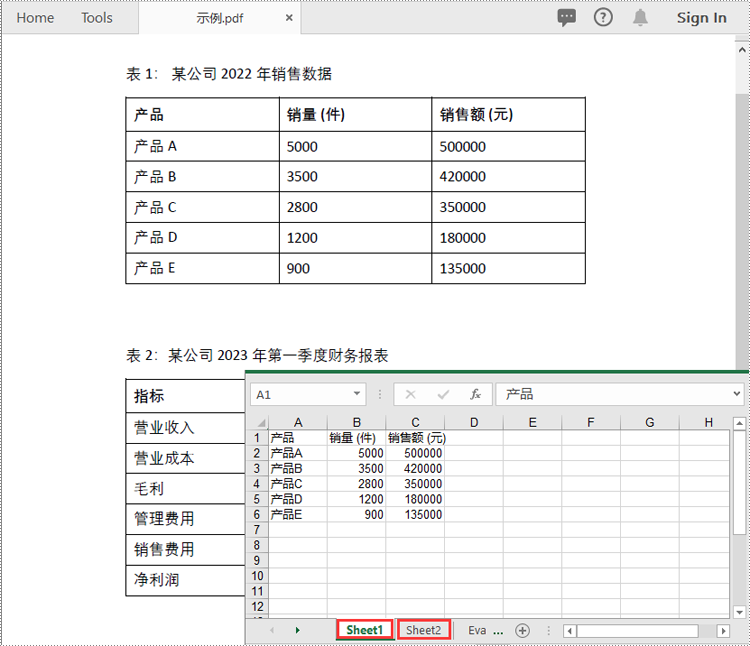
申请临时 license
如果您希望删除结果文档中的评估消息,或者摆脱功能限制,请该email地址已收到反垃圾邮件插件保护。要显示它您需要在浏览器中启用javascript。获取有效期 30 天的临时许可证。


