


word 文档中的批注通常用于协作审阅和提供反馈意见。这些批注可能包含有价值的文本和图片信息。提取批注中的文本和图片内容,可以帮助作者分析和评估审阅者的意见,从而全面了解文档的优缺点及改进建议。本文将介绍如何使用 spire.doc for python 在 python 中提取 word 文档批注中的文本和图片。
安装 spire.doc for python
本教程需要 spire.doc for python 和 plum-dispatch v1.7.4。您可以通过以下 pip 命令将它们轻松安装到 windows 中。
pip install spire.doc如果您不确定如何安装,请参考:如何在 windows 中安装 spire.doc for python
python 从 word 批注中提取文本
你可以使用 spire.doc for python 提供的 comment.format.author 和 comment.body.paragraphs[index].text 属性获取 word 批注的作者和文本。详细步骤如下:
- 创建 document 类的对象。
- 使用 document.loadfromfile() 方法加载 word 文档。
- 创建一个列表来存储提取的批注数据。
- 遍历文档中的批注。
- 遍历每个批注中的段落。
- 使用 comment.body.paragraphs[index].text 属性获取每个段落的文本。
- 使用 comment.format.author 属性获取批注的作者。
- 将批注的文本和作者添加到列表中。
- 将列表的内容保存到文本文件。
- python
from spire.doc import *
from spire.doc.common import *
# 创建一个 document 类的对象
document = document()
# 加载包含批注的 word 文档
document.loadfromfile("批注.docx")
# 创建一个列表来存储提取的批注数据
comments = []
# 遍历文档中的批注
for i in range(document.comments.count):
comment = document.comments[i]
comment_text = ""
# 遍历批注正文中的段落
for j in range(comment.body.paragraphs.count):
paragraph = comment.body.paragraphs[j]
comment_text = paragraph.text "\n"
# 获取批注作者
comment_author = comment.format.author
# 将批注数据添加到列表中
comments.append({
"作者": comment_author,
"内容": comment_text
})
# 将批注数据写入文件
with open("批注.txt", "w", encoding="utf-8") as file:
for i, comment in enumerate(comments, start=1):
file.write(f"批注{i}:\n 作者: {comment['作者']}\n 批注内容: {comment['内容']}\n")
document.close()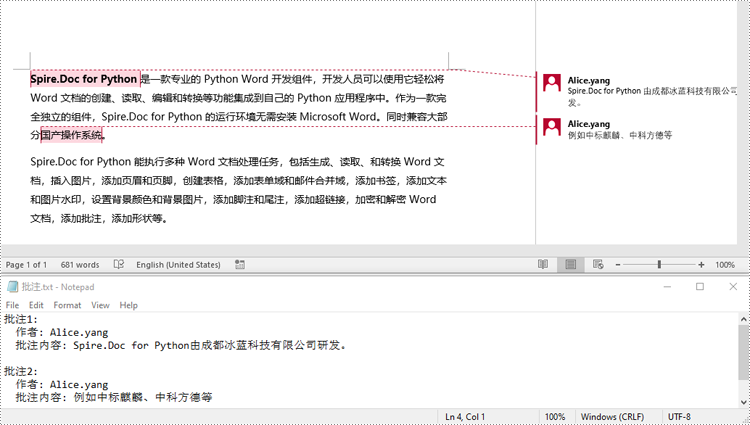
python 从 word 批注中提取图片
要从 word 批注中提取图片,需要遍历批注段落中的子对象,找到 docpicture 对象,然后使用 docpicture.imagebytes 属性获取图片数据,最后将图片数据保存为图片文件。
具体步骤如下:
- 创建 document 类的对象。
- 使用 document.loadfromfile() 方法加载 word 文档。
- 创建一个列表来存储提取的图片数据。
- 遍历文档中的批注。
- 遍历每个批注中的段落。
- 遍历每个段落的子对象。
- 检查对象是否为 docpicture 对象。
- 如果对象是 docpicture,使用 docpicture.imagebytes 属性获取图片数据,并将其添加到列表中。
- 将列表中的图片数据保存为单独的图片文件。
- python
from spire.doc import *
from spire.doc.common import *
# 创建一个 document 类的对象
document = document()
# 加载包含批注的 word 文档
document.loadfromfile("图片批注.docx")
# 创建一个列表来存储提取的图片数据
images = []
# 遍历文档中的批注
for i in range(document.comments.count):
comment = document.comments[i]
# 遍历批注正文中的段落
for j in range(comment.body.paragraphs.count):
paragraph = comment.body.paragraphs[j]
# 遍历段落中的子对象
for o in range(paragraph.childobjects.count):
obj = paragraph.childobjects[o]
# 查找图片
if isinstance(obj, docpicture):
picture = obj
# 获取图片数据并添加到列表中
data_bytes = picture.imagebytes
images.append(data_bytes)
# 将图片数据保存为图片文件
for i, image_data in enumerate(images):
file_name = f"批注图片-{i}.png"
with open(os.path.join("批注图片/", file_name), 'wb') as image_file:
image_file.write(image_data)
document.close()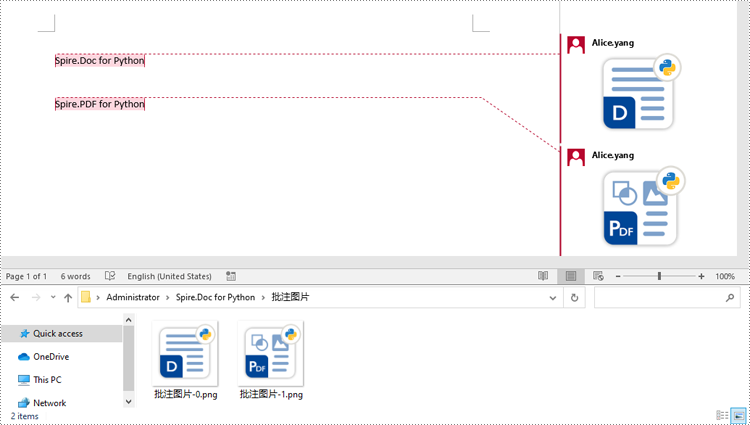
申请临时 license
如果您希望删除结果文档中的评估消息,或者摆脱功能限制,请该email地址已收到反垃圾邮件插件保护。要显示它您需要在浏览器中启用javascript。获取有效期 30 天的临时许可证。


