


从 1.9.8 版本开始,spire.ocr for .net 为开发人员提供了一个新的模型来从图片中提取文本。在本文中, 我们将演示如何使用 spire.ocr for .net 的新模型在 c# 中实现从图片中提取文本。
具体步骤如下:
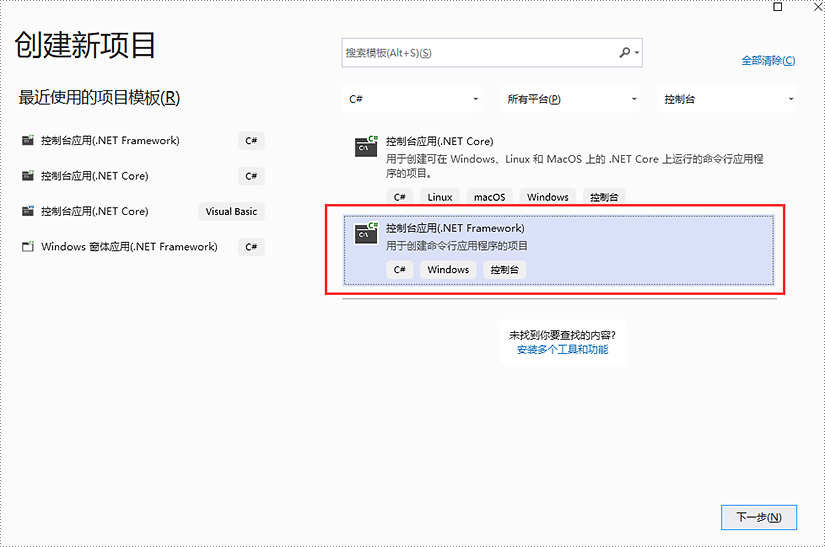
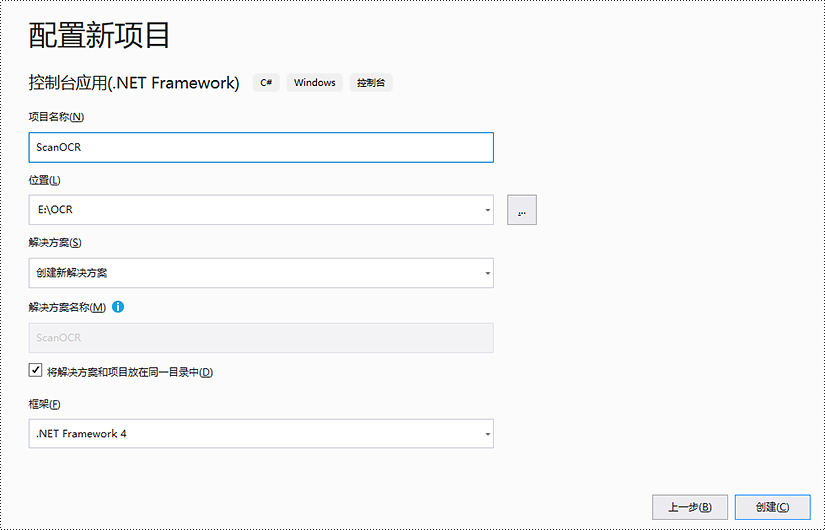
步骤 1:在 visual studio 中创建一个控制台应用(.net framework)。
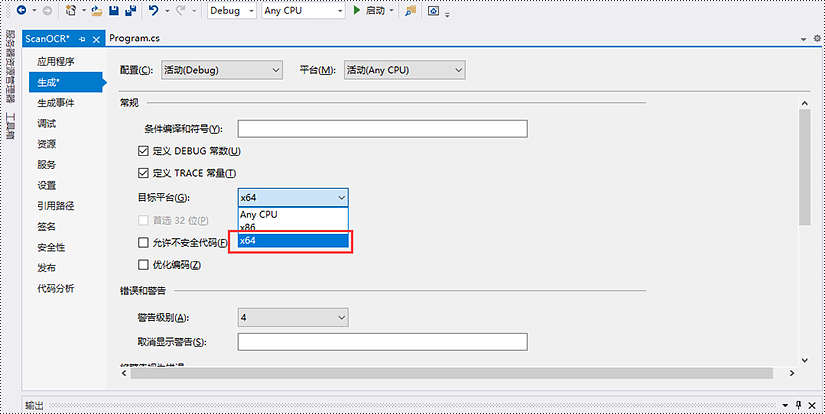
步骤 2:将应用程序的目标平台更改为 x64。
在应用程序的“ag凯发旗舰厅的解决方案资源管理器”中,右键单击项目名称,然后选择“属性”。
将应用程序的目标平台更改为 x64。 这一步必须执行,因为 spire.ocr 仅支持 64 位平台。
步骤 3:在程序中安装 spire.ocr for .net。
点击“工具”,选择“nuget包管理器“ -> “程序包管理器控制台”,然后在程序包管理器控制台中执行以下命令来安装 spire.ocr for .net:
install-package spire.ocr步骤 4:下载 spire.ocr for .net 的新模型和依赖项。
通过以下链接下载 spire.ocr for .net 的新模型和依赖项(model&lib.zip)。然后解压缩该包并保存到计算机上的特定目录(如“d:\”)。
https://www.e-iceblue.cn/resource/ocr_net/model&lib.zip
步骤 5:使用 spire.ocr for .net 的新模型实现从图片中提取文本。
以下代码示例展示了如何使用 spire.ocr for .net 的新模型实现从图片中提取文本:
- c#
using spire.ocr;
using system.io;
namespace scanocr
{
internal class program
{
static void main(string[] args)
{
// 设置许可证密钥
// spire.ocr.license.licenseprovider.setlicensekey("your-license-key");
// 创建 ocrscanner 类的实例
ocrscanner scanner = new ocrscanner();
// 创建 configureoptions 类的实例来设置扫描器配置
configureoptions configureoptions = new configureoptions();
// 设置新模型的路径
configureoptions.modelpath = @"d:\model&lib\model";
// 设置依赖库的路径
configureoptions.libpath = @"d:\model&lib\lib\x64";
// 指定文本识别的语言(例如english, chinese, chinesetraditional, french, german, japanese, or korean)
configureoptions.language = "english";
// 将配置应用于扫描器
scanner.configuredependencies(configureoptions);
// 从图片中提取文本
scanner.scan("测试.png");
// 将提取的文本保存到文本文件
string text = scanner.text.tostring();
file.writealltext("输出.txt", text);
}
}
}
申请临时 license
如果您希望删除结果文档中的评估消息,或者摆脱功能限制,请该email地址已收到反垃圾邮件插件保护。要显示它您需要在浏览器中启用javascript。获取有效期 30 天的临时许可证。


