在word文档中,我们可以通过最简单的方法来拆分word文档,那就是打开一个是需要拆分的文档的副本,删除我们不需要的内容然后将剩余内容保存为新文档到本地。虽然操作简单,但是一节一节的删除是个相当繁琐且枯燥的过程。利用spire.doc,我们可以程序化的根据分节符和分页符来拆分word文档,这避免了手动冗杂的操作。本文将对此做详细介绍。
根据分节符拆分文档
c#
//加载测试文档
document document = new document();
document.loadfromfile("测试文档.docx");
//拆分
document newword;
for (int i = 0; i < document.sections.count;i )
{
newword = new document();
newword.sections.add(document.sections[i].clone());
newword.savetofile(string.format("拆分结果/分节符拆分的结果文档_{0}.docx", i));
i = (i 1);
}vb.net
dim document as document = new document
document.loadfromfile("测试文档.docx")
dim newword as document
dim i as integer = 0
do while (i < document.sections.count)
newword = new document
newword.sections.add(document.sections(i).clone)
newword.savetofile(string.format("拆分结果\分节符拆分的结果文档_{0}.docx", i))
i = (i 1)
loop原文档如图,其中有两个分节符:
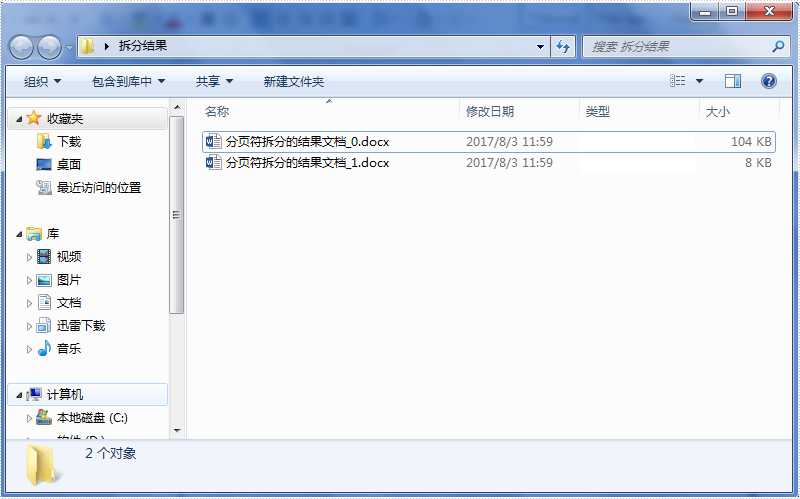
运行程序得到如下结果:
根据分页符拆分文档
c#
//加载源文档
document original = new document();
original.loadfromfile("c:/users/administrator/desktop/template.docx");
//创建一个新的文档并给它添加一个section
document newword = new document();
section section = newword.addsection();
int index = 0;
//遍历源文档的所有section,检测page break并根据page break拆分文档
foreach (section sec in original.sections)
{
foreach (documentobject obj in sec.body.childobjects)
{
if (obj is paragraph)
{
paragraph para = obj as paragraph;
section.body.childobjects.add(para.clone());
foreach (documentobject parobj in para.childobjects)
{
if (parobj is break && (parobj as break).breaktype == breaktype.pagebreak)
{
int i = para.childobjects.indexof(parobj);
for (int j = i; j < para.childobjects.count; j )
{
section.body.lastparagraph.childobjects.removeat(i);
}
newword.savetofile(string.format("c:/users/administrator/desktop/拆分结果/分页符拆分的结果文档-{0}.docx", index), fileformat.docx);
index ;
newword = new document();
section = newword.addsection();
section.body.childobjects.add(para.clone());
while (i >= 0)
{
section.paragraphs[0].childobjects.removeat(i);
i--;
}
if (section.paragraphs[0].childobjects.count == 0)
{
section.body.childobjects.removeat(0);
}
}
}
}
if (obj is table)
{
section.body.childobjects.add(obj.clone());
}
}
}
newword.savetofile(string.format("c:/users/administrator/desktop/拆分结果/分页符拆分的结果文档-{0}.docx", index), fileformat.docx);vb.net
dim original as document = new document
original.loadfromfile("c:\users\administrator\desktop\template.docx")
dim newword as document = new document
dim section as section = newword.addsection
dim index as integer = 0
for each sec as section in original.sections
for each obj as documentobject in sec.body.childobjects
if (typeof obj is paragraph) then
dim para as paragraph = ctype(obj,paragraph)
section.body.childobjects.add(para.clone)
for each parobj as documentobject in para.childobjects
if (typeof parobj is (break _
andalso (ctype(parobj,break).breaktype = breaktype.pagebreak))) then
dim i as integer = para.childobjects.indexof(parobj)
section.body.lastparagraph.childobjects.removeat(i)
newword.savetofile(string.format("c:\users\administrator\desktop\拆分结果\分页符拆分的结果文档_{0}.docx", index), fileformat.docx)
index = (index 1)
newword = new document
section = newword.addsection
section.body.childobjects.add(para.clone)
if (section.paragraphs(0).childobjects.count = 0) then
section.body.childobjects.removeat(0)
else
while (i >= 0)
section.paragraphs(0).childobjects.removeat(i)
i = (i - 1)
end while
end if
end if
next
end if
if (typeof obj is table) then
section.body.childobjects.add(obj.clone)
end if
next
next
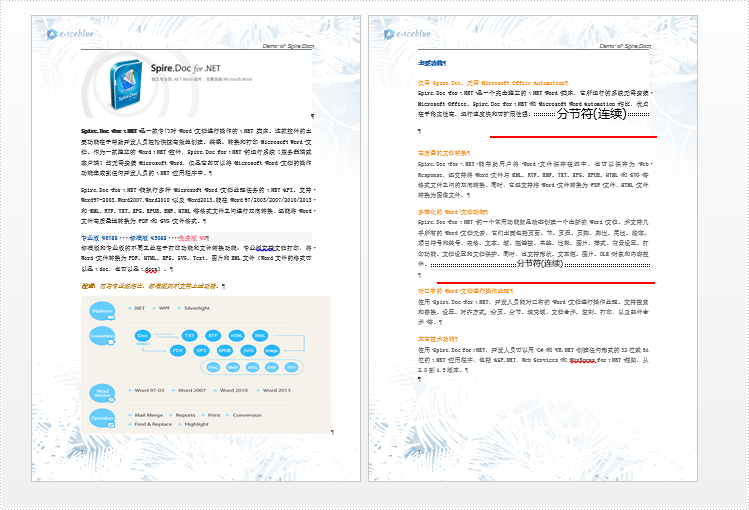
newword.savetofile(string.format("c:\users\administrator\desktop\拆分结果\分页符拆分的结果文档_{0}.docx", index), fileformat.docx)原文档如图,其中有一个分页符:

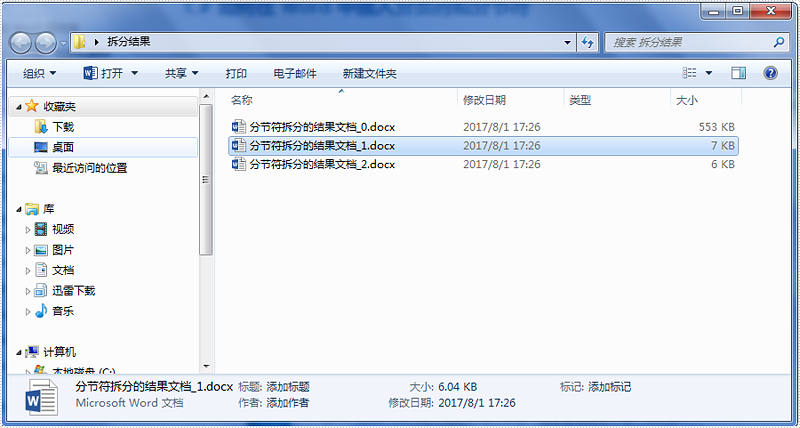
运行程序得到如下结果: